
Segmentation, targeting, and positioning are critical for marketers. Tailoring messaging, media, and products for specific customers can drive better responses and higher-quality customers. For marketers or business owners owning a specific piece of a larger business, it can be tempting to create “the perfect customer segmentations” to optimize that specific product, use case, or channel. However, this over-segmentation impulse is almost always a mistake.

To understand why this is the case, it’s necessary to look at three separate topics:
1) Factors and Dimension Reduction
A core principle of social science generally and psychology in particular—of which marketing is essentially a sub-discipline—is that there are a limited number of orthogonal underlying factors that reliably determine behaviors. Personality, for example, can be reliably explained by five factors, known as the “Big Five”—Openness, Conscientiousness, Agreeableness, Extroversion, and Neuroticism. Further breaking these factors down—or finding other dimensions of personality that are truly different from these—has rapidly diminishing returns and can be counterproductive.
The same theme holds for marketing. Different customer segmentations can be dressed up to sound different, but ultimately, a few factors will repeat themselves over again and again, across products, channels, and use cases. Inside an enterprise, different customer segmentations might sound necessary, but often, these repetitions are different clusters of the same factors. For example, one business unit might define five segments with clever names such as “Nervous Nellies”, “Confident Carls”, “Emotive Emilies”, “Bargain Seeking Brads”, and “Overwhelmed Omars.” Another unit might have five other segments with different names. However, in all likelihood, the same underlying factors—such as price sensitivity, savviness, and sensitivity—are driving both segments. They are only different because slightly different clustering techniques or assumptions were used in each case.
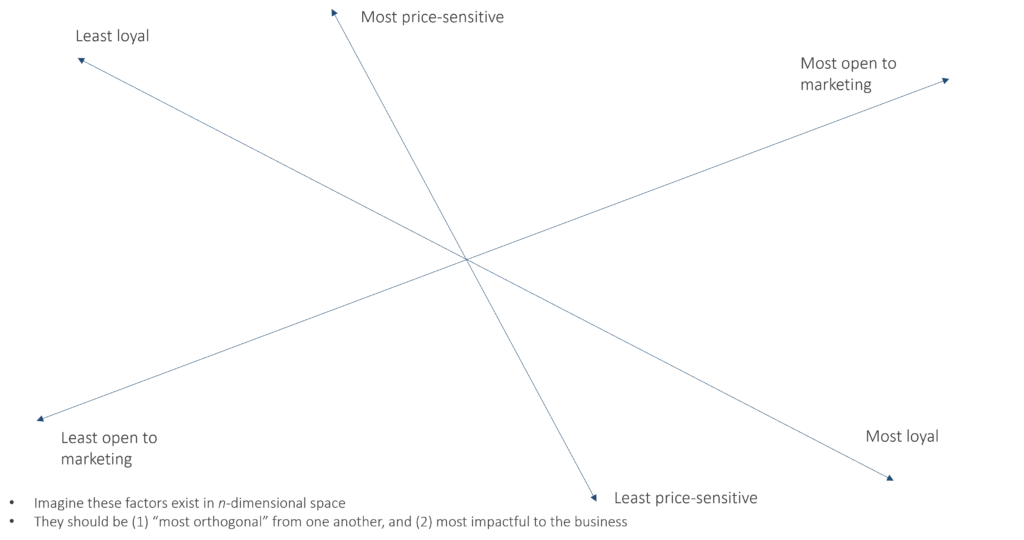
Furthermore, it’s not even necessary to create segments if underlying factors are well defined. Instead of giving segments clever names and marketing to one group, organizations should instead train marketers to think of the underlying factors—conscientiousness, openness to marketing, price sensitivity, etc.—that consistently drive behavior, and market to “high” or “low” intersections of these—as few as possible.
2) Knowability and Assignment
Just because a factor or segment is real, it doesn’t mean it’s findable in-market. This is less of an issue for a large consumer advertiser reaching huge audiences with big television buys; they can define their prime prospect attitudinally, and then blast a tailored message to a large audience, knowing that a good portion will be receptive to it. However, for direct marketers, or marketers seeking to use segmentation to create different messages for specific different individuals, this is impossible. It’s thus necessary to create models that find a segment using knowable data—also called “assignment.”
Assignment is very hard and sometimes is basically impossible. This is probably the number one reason that customer segmentations fail; they simply cannot be acted upon. There are several ways around this, but the simplest is to keep segmentation simple. If one underlying factor is something around price sensitivity, then use readily available income data to define the factor, rather than an over-complex multivariate solution that might have a bit more signal, but that is impossible to find in databases.

Even good machine learning classifiers struggle to bridge survey-based and behavioral data. Once in the real world, models suffer more, and get worse over time.
Another approach is skipping the attitudinal part altogether, and instead simply using readily available demographic data to find “maximum difference pockets.” This wouldn’t pass muster in a doctoral program, but for marketers, there’s a lot to like. For example, say we have reason to believe that income and net worth are top predictors of affinity for a certain product. There are other things that probably matter too, like education, and we might have found out in interviews that it’s not the money that drives affinity, but a stylish or luxury mindset. However, a perfect solution—doing factor analysis to find the perfect orthogonal vector that describes affinity—might not scale across all the use cases a marketer needs. It will be easier and more realistic to use an “A-“ proxy than to spend thousands of hours looking for a perfect solution that will have major implementation issues.
3) Stability Over Time
Machine learning models suffer from a very common problem that frustrates marketers—overfitting. For the analyst, getting a more accurate model is the goal. However, adding more features to a model to get an extra point or two of accuracy comes with serious risk. Overfitting is not a mistake, per se—it just means that the model will be “over-tuned” for the specific data set being used. Overfitting is like turning an amplifier to its highest level to tune to a signal. When the signal is precisely tuned, it will sound great. However, even the slightest change in the environment will cause feedback and loud static.
This problem is particularly acute for segmentation. A segmentation created via a survey instrument is measured at a point in time with precise questions. When assigning out to the larger universe, even more uncertainty is added, because analysts are forced to rely upon modeled data with high error rates. The result can be a segmentation that looks good on its surface, but is brittle over time. A key test for this problem is re-running segmentation assignment algorithms over months to measure the percentage of individuals who move from segment to segment. Movements of more than a few percentage points are a big warning sign.
The Solution: Keep it Simple
For most organizations, one segmentation is enough. It is true that it won’t be the most precise solution for all use cases, but one segmentation—or set of factors—will help marketers and business leaders streamline their processes, and will prevent needless waste. A single, simple segmentation should:
- Be stable over time
- Be assignable and knowable for all (or most) use cases
- Use knowable, simple data wherever possible
- Be simple and easily explainable
- Potentially be made up of 2-3 clearly defined and knowable factors, instead of a clustering solution

Download our framework, “10 Steps for Building Foolproof Customer Segmentations”
Download the framework for 10 steps to avoid bad segmentations–ones that are hard to describe, unactionable in business processes, too broad or too specific, and become obsolete quickly.


